Mahout驾驭hadoop之详解
本文共 572 字,大约阅读时间需要 1 分钟。
众所周知,Mahout是基于Hadoop分布式系统的,要想看懂Mahout的源码,首先得明白mahout是如何使用hadoop的!
首先,在我的<<Hadoop运行原理详解>>一篇中,详细介绍了hadoop的运行机制,这里就不多说了!下面我就以Kmeans聚类算法为例,讲讲mahout如何利用hadoop实现数据挖掘算法并行化.如以下类图所示,
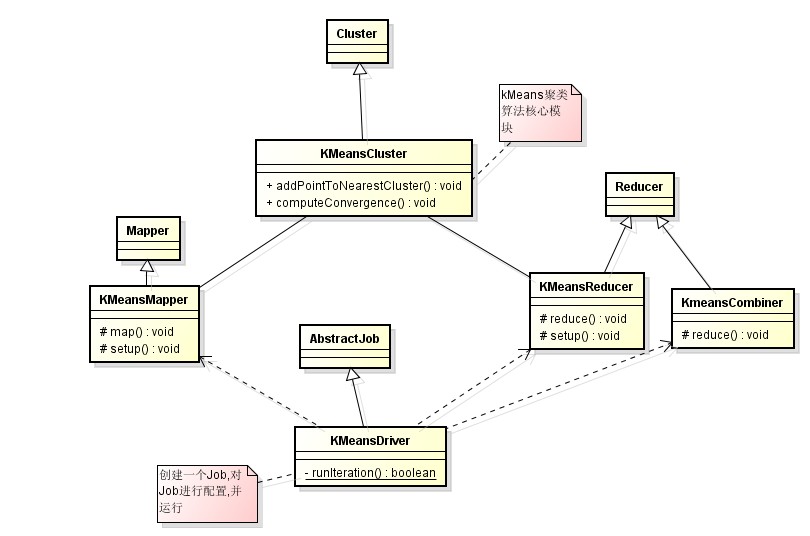
该图描述了整个mahout实现Kmeans算法的架构图,首先KmeansCluster继承Cluster,在KmeansCluster中有几个比较重要的方法,首先clusterPoints()是实现Kmeans聚类算法的方法,而其中调用了runKMeansIteration()方法,该方法是单次聚类迭代方法.
尤其可见,这块算法实现和普通kmeans算法没有太大差别!在Mahout针对每个算法都有一个Driver,这个东西是干什么的啊?
我们先看看KMeansDriver源码,KmeansDriver继承了AbstractJob.我们知道Hadoop上的任务都是以Job的形式启动的!我们要使用某个算法进行一项数据挖掘工作,因此就要启动一个Job.因此,KmeansDriver就是创建一个Job,然后对Job的属性进行配置,然后运行该Job.

上图反映了KMeansDriver工作原理.
转载地址:http://ajbva.baihongyu.com/
你可能感兴趣的文章
java jvm GC 各个区内存参数设置
查看>>
[使用帮助] PHPCMS V9内容模块PC标签调用说明
查看>>
关于FreeBSD的CVSROOT的配置
查看>>
基于RBAC权限管理
查看>>
基于Internet的软件工程策略
查看>>
数学公式的英语读法
查看>>
留德十年
查看>>
迷人的卡耐基说话术
查看>>
PHP导出table为xls出现乱码解决方法
查看>>
PHP问题 —— 丢失SESSION
查看>>
Java中Object类的equals()和hashCode()方法深入解析
查看>>
数据库
查看>>
Vue------第二天(计算属性、侦听器、绑定Class、绑定Style)
查看>>
dojo.mixin(混合进)、dojo.extend、dojo.declare
查看>>
Python 数据类型
查看>>
iOS--环信集成并修改头像和昵称(需要自己的服务器)
查看>>
PHP版微信权限验证配置,音频文件下载,FFmpeg转码,上传OSS和删除转存服务器本地文件...
查看>>
教程前言 - 回归宣言
查看>>
PHP 7.1是否支持操作符重载?
查看>>
Vue.js 中v-for和v-if一起使用,来判断select中的option为选中项
查看>>